.svg)
When Every I/O Counts: How Altius Found and Started Optimizing Reth’s Database Performance


At Altius, we spend a lot of time thinking about performance. We envision a world where blockchain infrastructure behaves more like high-frequency trading systems - parallelized, memory-first, and allergic to unnecessary I/O.
So when we started digging into Paradigm’s Reth codebase, it wasn’t just curiosity. We were evaluating how to cleanly insert a modular, scalable state layer under existing EVM engines, one that supports our work on Parallel Scalable Storage (PSS) and distributed Merkle trie sharding.
What we found surprised us.

The Bottleneck We Didn’t Expect
We noticed something strange when inspecting how Reth handles database access, especially during state reads. Even for simple account lookups, the engine was issuing unnecessary calls to the database, calls that could’ve been completely short-circuited and skipped.
In systems like Reth, where state is stored in a Merkle-Patricia Trie (MPT) and backed by disk, every extra DB call have real costs in terms of disk latency. And in Reth’s case, we were noticing substantial unnecessary disk access.
So we opened GitHub Issue #14558 in the reth repo. We documented the behavior, explained the performance impact, and even suggested various optimizations some using Paradigm’s own existing data structures.
What We Found—and How We Improved It Together!
After one quick reply in the github issue with a suggestion that didn’t pan out, we didn’t get any more updates. Since this was obviously impeding our own goals, we decided to just dive into the code and figure it out. Note that the diagrams below discusses the various entries in the MDBX database1 that a typical account lookup touches to get to the final information for the actual account. Not surprisingly, the actual DB layout is well thought out, and the AccountsTrie table mirrors Ethereum’s MPT. This made things surprising when we discovered what was going on under the hood. To figure this out, we added tracing logs msgs to every database access we could find and literally tracked all of them until we figured out what was happening.
We’d love to dive into (extra) gory details, but it’s probably easier to just look at the difference between our implementations by looking at how the trie walk is done. Again, kudos to the DB layout, we discovered there were bitmasks stored in each of the nodes that more or less indicate exactly what is or isn’t present in the nodes directly under it . So instead of walking large sections of the trie, instead we only walk what was necessary. This is reth v1.3.2:
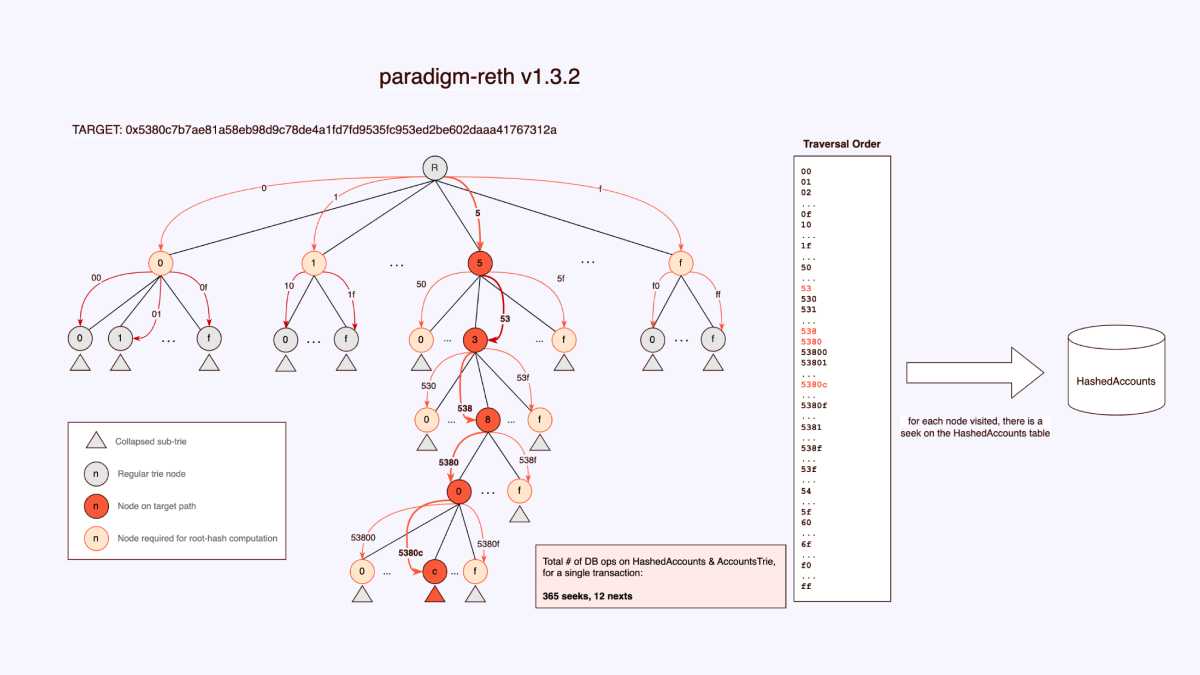
For example, at the top level, even though we know that we will need all the 1st level nodes to calculate the root hash after updating the MPT, and even though the available bitmasks already tell us these nodes exist, reth still continues to seek across every node. There isn’t a full on visiting of every node, but many nodes are visited unnecessarily . Let’s move on to our solution. We do the simple thing one would expect to do!
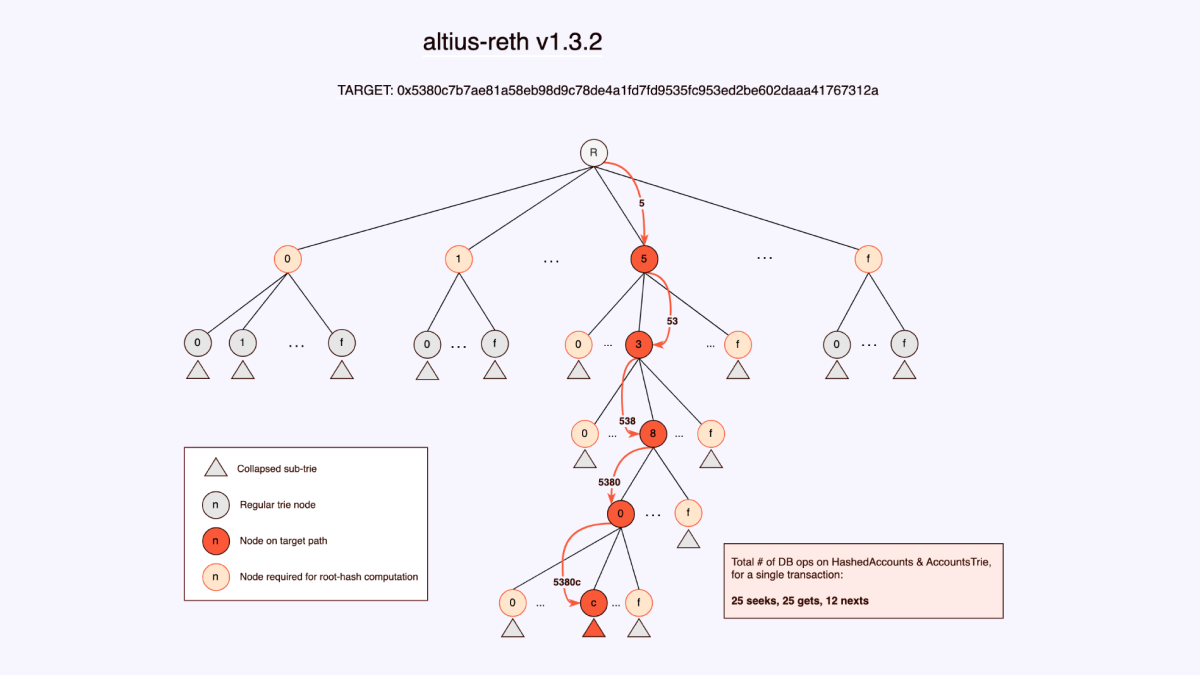
We use the existing information embedded in each nodes’ bitmasks, to figure out if the corresponding node exists in the HashedAccounts table. And in addition, we simply walk down the tree to all the nodes we need to calculate the root hash.
As you can see in the diagrams, there is an order of magnitude less DB operations. And as we know, every disk access we can avoid is paramount to the speed of any execution layer. The above diagrams are the result of one random transaction that we traced. Of course, 1 transaction is not a real metric, so we traced between 500 and 1000 blocks and saw between 70% - 80% improvement over various block ranges. But what matters is actual disk iops so we analyzed that next.
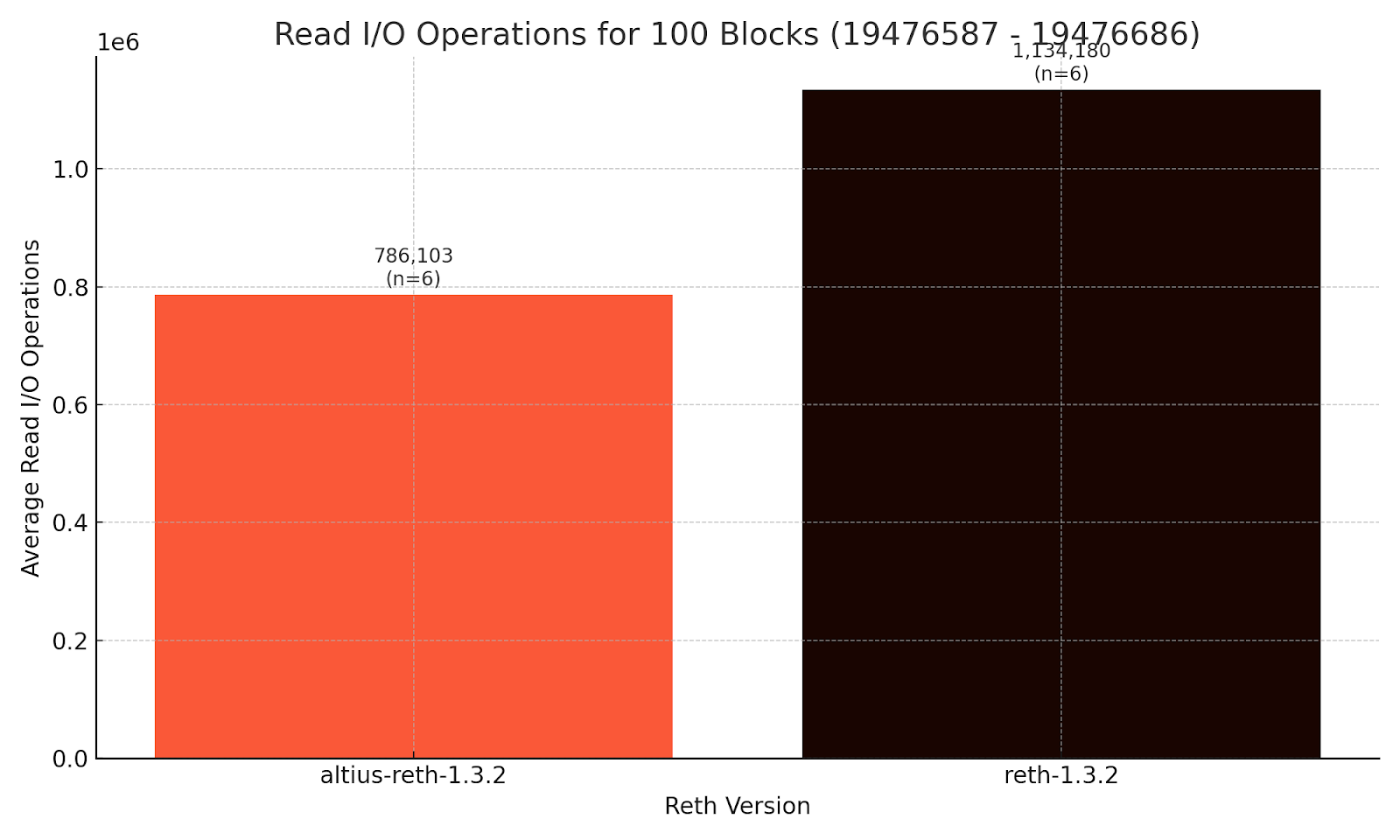
The translation of these DB operations into read iops reduction led us to test performance of executing 100 blocks (19476587 - 19476686) and utilizing Linux cgroups to isolate reth iops performance during execution. For our tests, we performed 12 runs that first clear disk caches, isolate iops to the reth process and mdbx database on an nvme storage device, and then average the middle 6 runs (dropping the first 3 and last 3 with a standard practice called interquartile range or IQR). This work was done on a standard Amazon Web Services EC2 instance (i8g.4xlarge). The result is we saw a 44% reduction in read IOPs from our optimizations.
Why We Were Looking at This in the First Place
At Altius, our architecture is built around a few core ideas:
- Execution should be parallel. Sequential transaction processing fails to utilize a full processor’s computing power, but this requires account information to be available before a transaction needs it!
- State should be as much as possible in-memory and smartly cached.
- Disk I/O is the enemy of performance. Especially under contention.
That’s why we’re building Parallel Scalable Storage, which includes a distributed, memory-first implementation of the Merkle trie. The end goal is to let execution layers treat our system like a black box: fast, reliable, and horizontally scalable. But to do that, we need a clean abstraction boundary, and clean abstractions demand predictable behavior from the upstream code. Which is why, after seeing the DB access patterns in Reth, we decided to fix them ourselves.
What This Enables
With a more consistent optimized access pattern in place, Altius’ state engine can slot in underneath existing clients. For chains using Reth, this means:
- Immediate I/O reduction with no change to consensus or VM.
- Support for distributed trie storage - run your state across multiple nodes instead of one.
- Better developer ergonomics for testing state modules in isolation.
We’re continuing to build out the adapter layer and plan to open-source the integration work.
We Believe in Open Performance
This isn’t about credit. It’s about execution performance. This post isn’t a call-out. It’s a call-in.
Paradigm’s Reth is a great piece of engineering, and part of the reason it exists is so the community can contribute and collaborate. We’ll keep surfacing things we find. And we’ll keep building modular, open components that let any chain scale execution without rebuilding the world from scratch.
Because at the end of the day, every I/O still counts.
Reth Team’s Improvement Update
After about 3 weeks, while we worked diligently on our own solution, there was actually an update to the github issue. It turns out our investigation and analysis had opened the door to fantastic improvements. It looks like our solution takes a slightly different tack, but using the same ideas, the Paradigm team has added similar optimizations to reth.
As a team that has recently just started building with reth, we’re still conservative in how well we’re doing. We usually start from a position of assuming that we are wrong, and there must be a reason the way something is. Seeing we were in fact correct definitely gives us greater confidence that we’re heading in the right track!
Footnotes: (1) in MDBX jargon, tables are called databases and databases are called environments. But to make it conceptually easier for most readers who might not have used MDBX before, I’ve referred to MDBX as the database, and environments as tables. Ref. https://pkg.go.dev/github.com/torquem-ch/mdbx-go/mdbx